3
Basicão
Basicão
O R como calculadora
2 + 3## [1] 52/3## [1] 0.66666672*3## [1] 62^3## [1] 8log10(9)## [1] 0.9542425log(9)## [1] 2.197225((4+16)/4)^2## [1] 25Ajuda no R
# help.search("Logarithms")Com esse comando o R irá procurar, dentro dos arquivos de help, possíveis funções para calcular logaritmos. Uma janela irá se abrir contendo possíveis funções. Nas versões mais recentes do R a função help.search() pode ser substituída por apenas ?? (duas interrogações)
# ??logarithmsTambém é possível buscar ajuda na internet, no site do R, com a função RSiteSearch()
# RSiteSearch("logarithms")Para ver os arquivos de ajuda do R use o comando help(nome.da.função) ou ?nome.da.funcão. Por exemplo, vamos ver o help da função log:
# help(log)ou simplesmente
?logGeralmente, o arquivo de help do R possui 10 tópicos básicos:
1 - Description - faz um resumo geral sobre o uso da função 2 - Usage - mostra como a função deve ser utilizada e quais argumentos podem ser especificados 3 - Arguments - explica o que é cada um dos argumentos 4 - Details - explica alguns detalhes sobre o uso e aplicação da função (geralmente poucos) 5 - Value - mostra o que sai no output após usar a função (os resultados) 6 - Note - notas sobre a função 7 - Authors - lista os autores da função (quem escreveu os códigos em R) 8 - References - referências para os métodos usados 9 - See also - mostra outras funções relacionadas que podem ser consultadas 10 - Examples - exemplos do uso da função. Copie e cole os exemplos no R para ver como funciona Quando for usar uma função pela primeira vez será no help que você aprenderá a usá-la. Os tópicos Usage e Arguments são os mais importantes, pois mostram como os argumentos devem ser inseridos na função (Usage) e caso não saiba o que é algum desses argumentos existe uma explicação para cada um deles (Arguments). Inicialmente, muitas pessoas têm dificuldade em entender o help do R e dizem que ele é R é ruim. Porém, com a prática os usuários percebem que help possui tudo que você precisa saber. Nada a mais nem nada a menos que o necessário. É fundamental aprender a usar o help para um bom uso do R.
Usando algumas funções
sqrt(9) # Tira a raiz quadrada dos argumentos entre parênteses, no caso 9## [1] 3 sqrt(3*3^2) # raiz quadrada de 27## [1] 5.196152 sqrt((3*3)^2)# raiz quadrada de 81## [1] 9 #prod é a função para multiplicação
prod(2,2) # O mesmo que 2x2## [1] 4 prod(2,2,3,4)# 2x2x3x4## [1] 48 log(3) # log natural de 3## [1] 1.098612 log(3,10)# log de 3 na base 10## [1] 0.4771213 log10(3)# o mesmo que acima! log 3 na base 10## [1] 0.4771213Módulo
abs(3-9)## [1] 6Fatorial
factorial(4)## [1] 24Vetores
medidas<-c(22,28,37,34,13,24,39,5,33,32)
class(medidas)## [1] "numeric"letras<-c("a","b","c","da","edw")
class(letras)## [1] "character"palavras<-c("Manaus","Boa Vista","Belém","Brasília")
class(palavras)## [1] "character"Operações com vetores
max(medidas) ## [1] 39min(medidas)## [1] 5sum(medidas)## [1] 267medidas^2 ## [1] 484 784 1369 1156 169 576 1521 25 1089 1024medidas/10## [1] 2.2 2.8 3.7 3.4 1.3 2.4 3.9 0.5 3.3 3.2mean(medidas)## [1] 26.7sd(medidas)## [1] 10.89393median(medidas)## [1] 30n.medidas<-length(medidas)
n.medidas## [1] 10media.medidas<-sum(medidas)/n.medidas
media.medidas## [1] 26.7medidas[5]## [1] 13palavras[2]## [1] "Boa Vista"medidas[c(5,8,10)]## [1] 13 5 32medidas[-1] ## [1] 28 37 34 13 24 39 5 33 32medidas[1]<-100Listar e remover objetos salvos
Para listar os objetos que já foram salvos use ls() que significa listar.
ls()## [1] "letras" "media.medidas" "medidas" "n.medidas"
## [5] "palavras"Para remover objetos use rm() para remover o que está entre parênteses.
rm(media.medidas)
rm(n.medidas)Gerar Sequências
1:10## [1] 1 2 3 4 5 6 7 8 9 10a = 13:15
a## [1] 13 14 15Vamos criar uma seqüência de 1 a 10 pegando valores de 2 em 2.
seq(1,10,2)## [1] 1 3 5 7 9Ou ainda:
seq(from = 1, to = 10, by = 2 )## [1] 1 3 5 7 9Gerar repetições (rep)
Vamos usar a função rep para repetir algo n vezes.
rep(5,10)## [1] 5 5 5 5 5 5 5 5 5 5A função rep funciona assim: rep(x, times=y) # rep(repita x, y vezes) # onde x é o valor ou conjunto de valores que deve ser repetido, e times é o número de vezes)
rep("a",5) # repete a letra "a" 5 vezes## [1] "a" "a" "a" "a" "a" rep(1:4,2) # repete a seqüência de 1 a 4 duas vezes## [1] 1 2 3 4 1 2 3 4 rep(1:4,each=2) # note a diferença ao usar o comando each=2## [1] 1 1 2 2 3 3 4 4 rep(c("A","B"),5) # repete A e B cinco vezes.## [1] "A" "B" "A" "B" "A" "B" "A" "B" "A" "B" rep(c("A","B"),each=5) # repete A e B cinco vezes.## [1] "A" "A" "A" "A" "A" "B" "B" "B" "B" "B" rep(c("Três","Dois","Sete","Quatro"),c(3,2,7,4)) # Veja que neste## [1] "Três" "Três" "Três" "Dois" "Dois" "Sete" "Sete" "Sete"
## [9] "Sete" "Sete" "Sete" "Sete" "Quatro" "Quatro" "Quatro" "Quatro"Gerar dados aleatórios
runif (Gerar dados aleatórios com distribuição uniforme)
runif(15, min=0, max=1) # gera uma distribuição uniforme com n valores, começando em min e terminando em max## [1] 0.83082186 0.29298528 0.52750570 0.61580584 0.69283495 0.55885727
## [7] 0.80730755 0.77824790 0.92804545 0.88591339 0.33687596 0.09139498
## [13] 0.03183955 0.72338537 0.74756298temp<-runif(200,80,100)
hist(temp)
rnorm (Gerar dados aleatórios com distribuição normal)
rnorm(10, mean=0, sd=1)## [1] 0.6732462 -0.4332747 -0.5421577 0.4718428 1.3379071 -0.2867307
## [7] 1.8880332 0.2809374 0.6251362 -1.5171912temp2<-rnorm(200,8,10)
hist(temp2)
Fazer amostras aleatórias
A função sample é utilizada para realizar amostras aleatórias e funciona assim: sample(x, size=1, replace = FALSE)# onde x é o conjunto de dados do qual as amostras serão retiradas, size é o número de amostras e replace é onde você indica se a amostra deve ser feita com reposição (TRUE) ou sem reposição (FALSE).
sample(1:10,5)## [1] 3 5 1 9 8# sample(1:10,15)
sample(1:10,15,replace=TRUE) ## [1] 6 8 8 2 4 9 8 6 2 9 1 1 10 6 9moeda<-c("CARA","COROA")
#sample(moeda,10)
sample(moeda,10,replace=TRUE) ## [1] "CARA" "COROA" "CARA" "COROA" "CARA" "CARA" "COROA" "CARA" "COROA"
## [10] "CARA"Gráficos
Gráficos de Barras
barplot(sample(10:100,10))
Pizza
pie(c(1,5,7,10))
#pie(rep(1, 24), col = rainbow(24), radius = 0.9)Gráfico de pontos (gráficos de dispersão)
Gráficos com variáveis numéricas
Primeiro vamos inserir os dados de duas variáveis numéricas. Lembre que a forma mais simples de inserir dados no R é usando a função de concatenar dados “c”.
y<-c(110,120,90,70,50,80,40,40,50,30)
x<-1:10
plot(x,y) 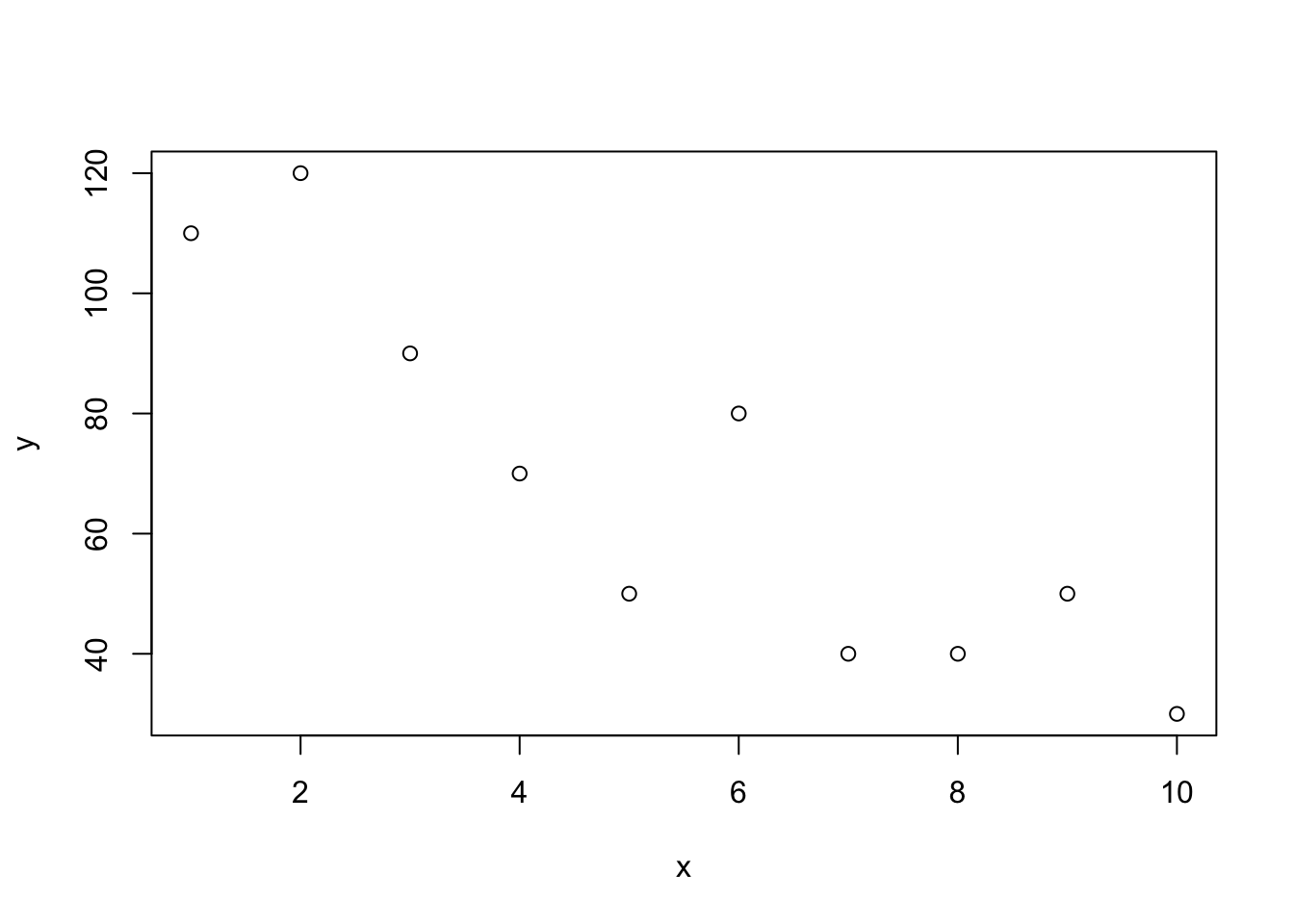
Alterando a aparência do gráfico
publicações é necessário saber melhorar a aparência do gráfico. Sempre é bom ter nomes informativos nos eixos (no R a opção default de nome das legendas é o próprio nome das variáveis). Suponha então que queremos mudar o nome da variável do eixo x para “Variável explanatória”. Para isso, o argumento xlab (“x label”) é utilizado. Use as setas do teclado para voltar ao comando anterior e coloque uma “vírgula” após o y e depois da vírgula coloque o comando da legenda do eixo x (xlab=“Variável explanatória”)
plot(x,y,xlab="Var explanatória",ylab="Var resposta")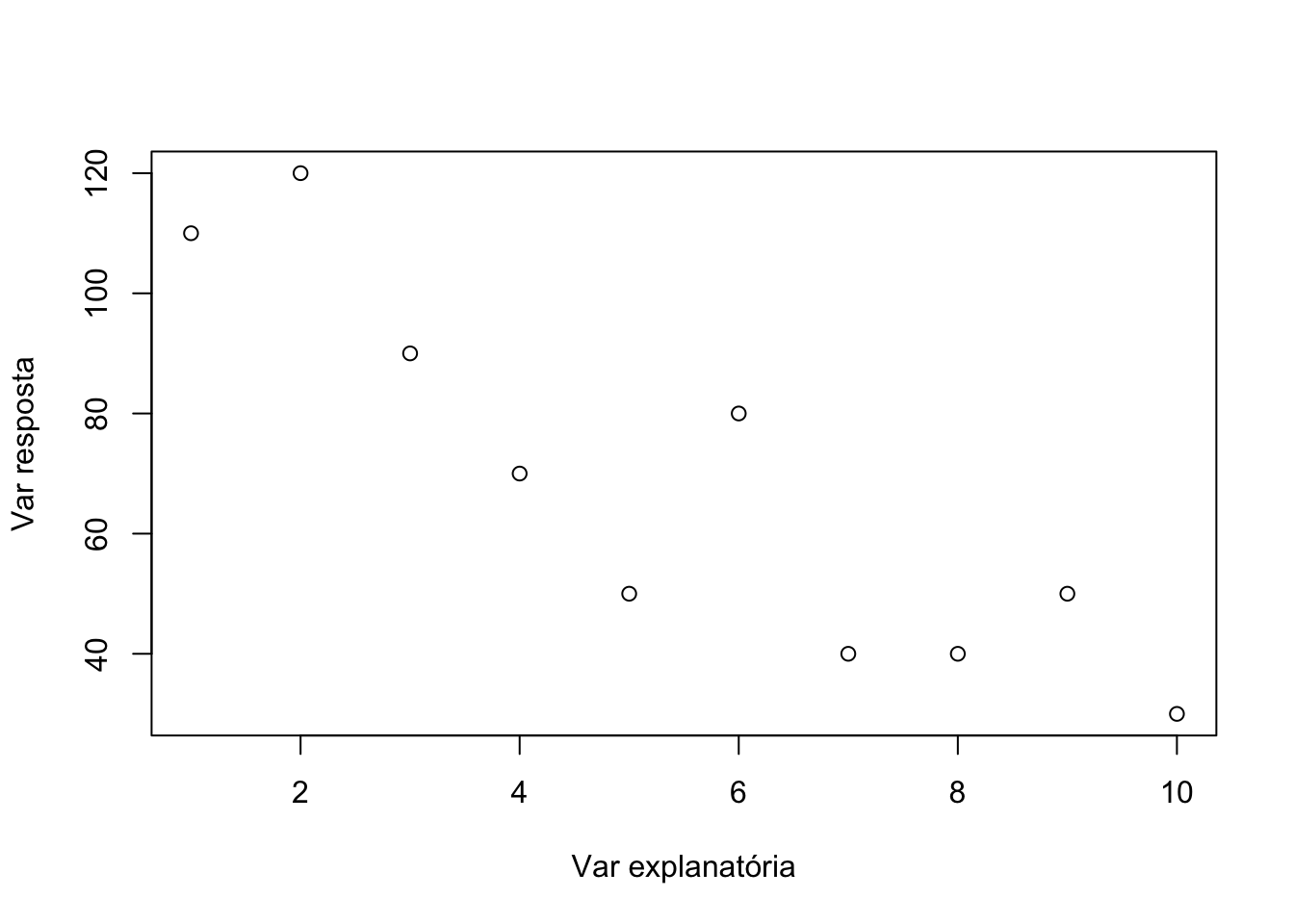 Adicionando estética
Adicionando estética
plot(x,y,xlab="Var explanatória",ylab="Var resposta" ,pch=4)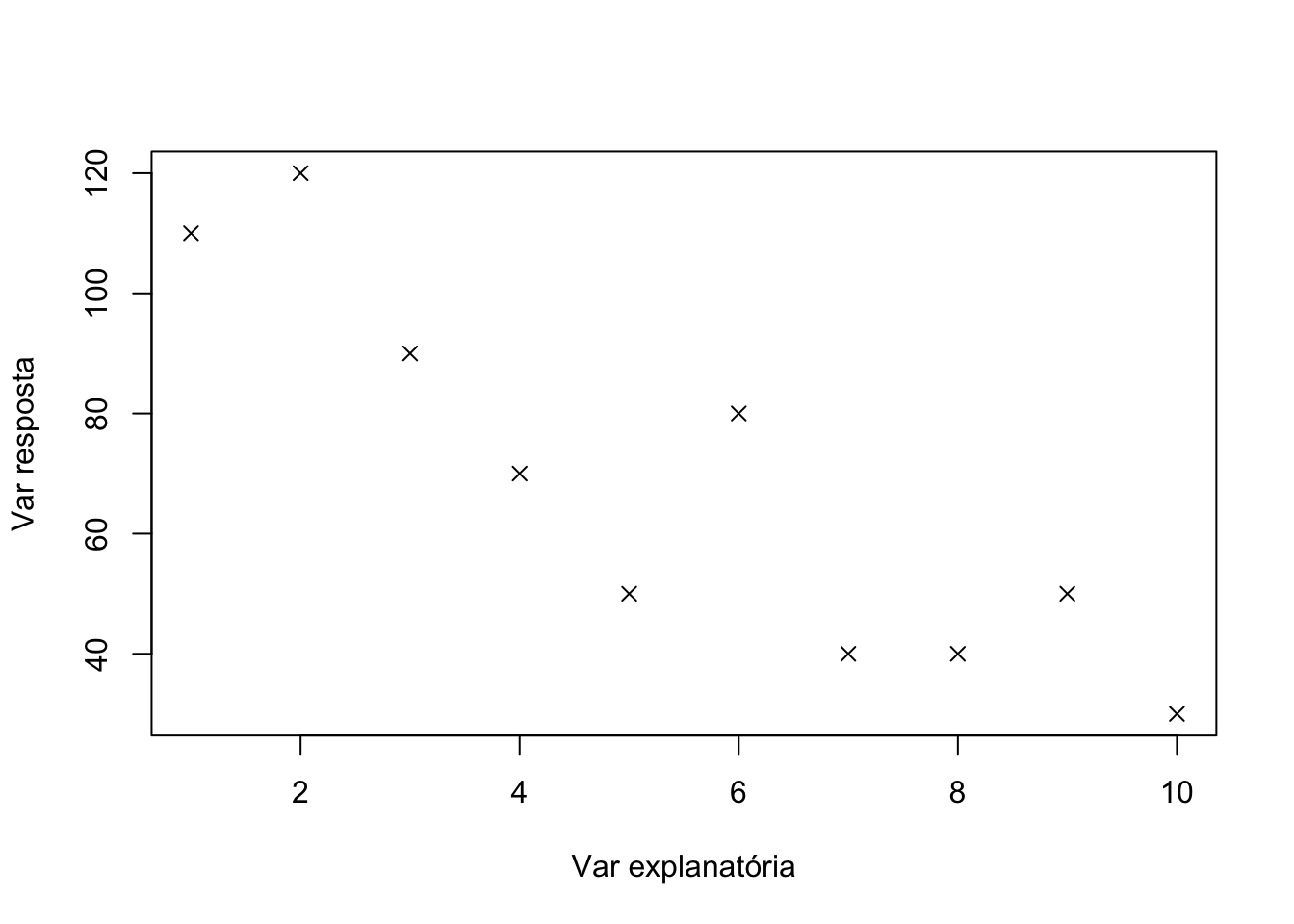
Adicionando título
plot(x,y,xlab="Var explanatória",ylab="Var resposta" ,pch=4,
main="Título do gráfico")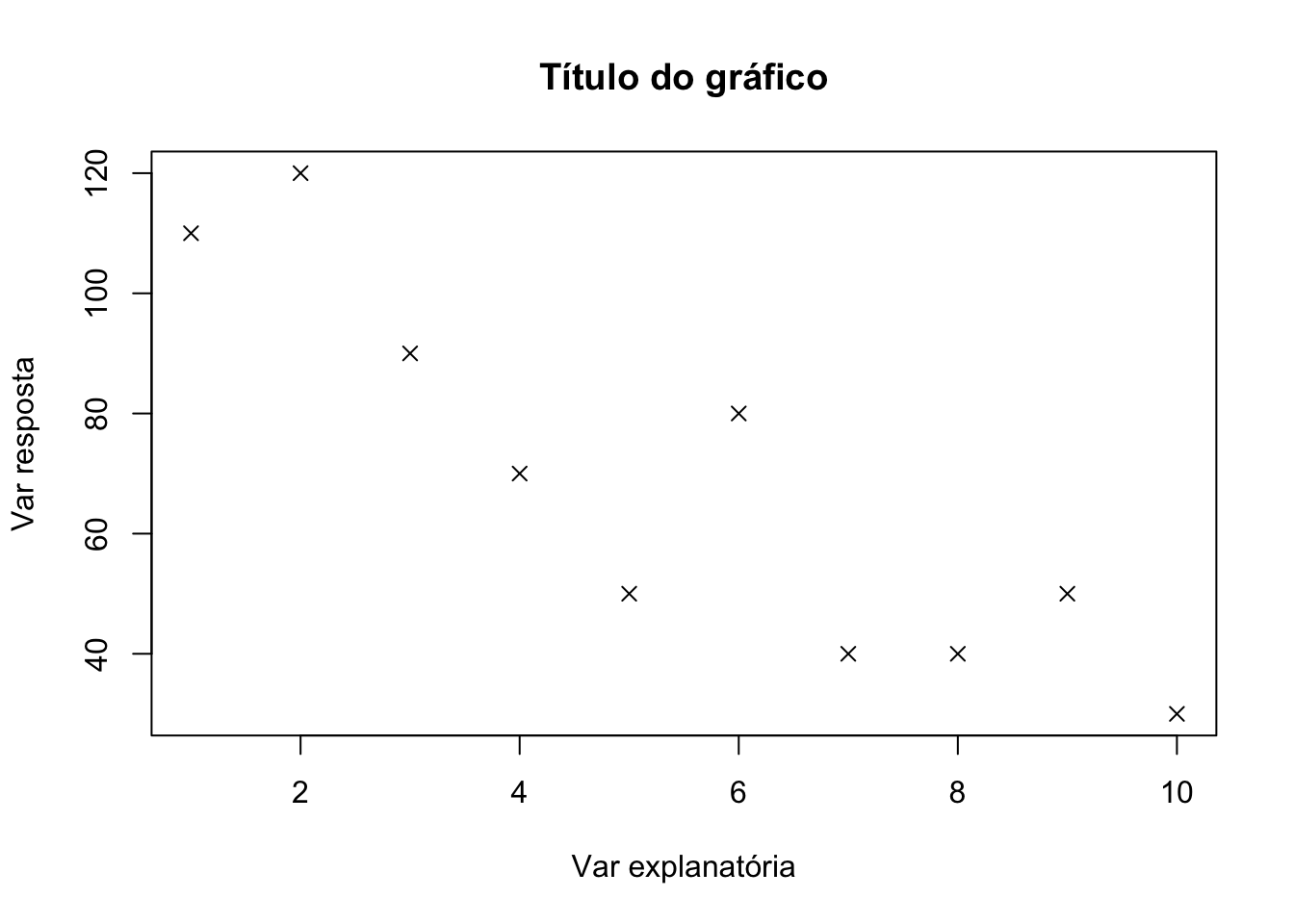 Adicionando as médias de X e Y:
Adicionando as médias de X e Y:
plot(x,y,xlab="Var explanatória",ylab="Var resposta" ,pch=4,
main="Título do gráfico")
abline(h=mean(y))
abline(v=mean(x))
Vamos passar uma linha que passa pelo sétimo valor do eixo x e mudar a cor da linha:
plot(x,y,xlab="Var explanatória",ylab="Var resposta" ,pch=4,
main="Título do gráfico")
abline(h=mean(y))
abline(v=mean(x))
abline(v=7, col="red")#
Reunindo todos
plot(x,y,xlab="Var explanatória",ylab="Var resposta" ,pch=4,
main="Título do gráfico")
abline(h=mean(y), v=mean(x),col=c(2,4)) ### Adicionar mais pontos ao gráfico Em alguns casos podemos querer inserir pontos de outro local no mesmo gráfico, usando símbolos diferentes para o novo local. Suponha que temos novos valores da variável resposta e da variável explanatória, coletados em outro local, e queremos adicionar estes valores no gráfico. Os valores são
### Adicionar mais pontos ao gráfico Em alguns casos podemos querer inserir pontos de outro local no mesmo gráfico, usando símbolos diferentes para o novo local. Suponha que temos novos valores da variável resposta e da variável explanatória, coletados em outro local, e queremos adicionar estes valores no gráfico. Os valores são
v<-c(3,4,6,8,9)
w<-c(80,50,60,60,70)Para adicionar estes pontos ao gráfico, basta usar a função points(), e usar uma cor diferente para diferenciar. Primeiro vamos refazer o gráfico com x e y e depois adicionar os novos pontos.
plot(x,y)
points(v,w,col="blue")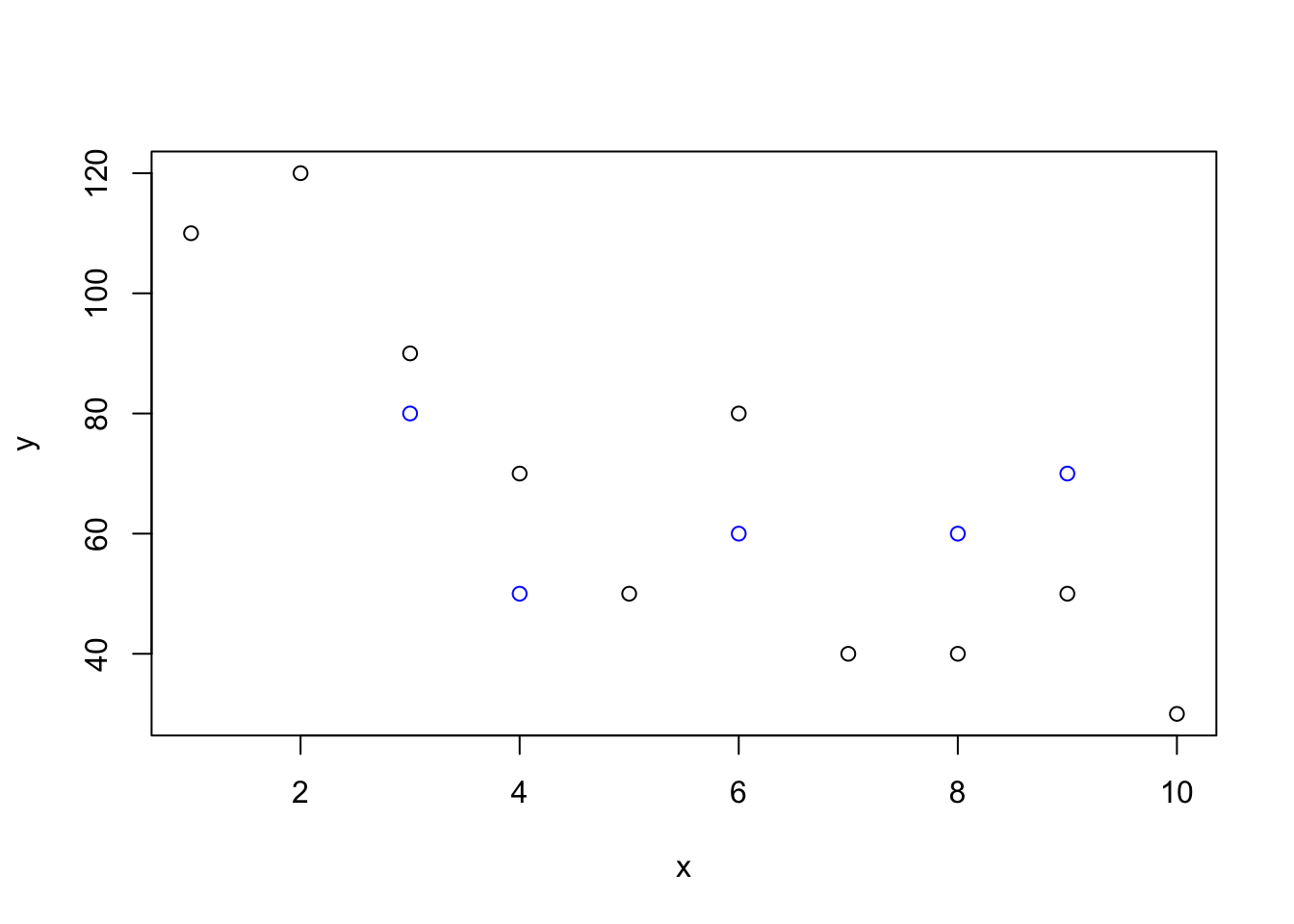
Gráficos com variáveis explanatórias que são categóricas.
Variáveis categóricas são fatores com dois ou mais níveis (você verá isso no curso de estatística). Por exemplo, sexo é um fator com dois níveis (macho e fêmea). Podemos criar uma variável que indica o sexo como isto: sex<-c(“macho”,“fêmea”) A variável categórica é o fator sexo e os dois níveis são “macho” e “fêmea”. Em princípio, os níveis do fator podem ser nomes ou números (1 para macho e 2 para fêmea). Use sempre nomes para facilitar. Vamos supor que os 5 primeiros valores da nossa variável y eram machos e os 5 últimos eram fêmeas e criar a variável que informa isso.
sexo<-c("Ma","Ma","Ma","Ma","Ma","Fe","Fe","Fe","Fe", "Fe")
peso<-y
sexo## [1] "Ma" "Ma" "Ma" "Ma" "Ma" "Fe" "Fe" "Fe" "Fe" "Fe"peso## [1] 110 120 90 70 50 80 40 40 50 30Plotando os dados
#plot(sexo,peso)Observe que o comando não funcionou, deu erro! Isso ocorreu porque não informamos que sexo é um fator. Vamos verificar o que o R acha que é a variável sexo.
is(sexo)## [1] "character" "vector" "data.frameRowLabels"
## [4] "SuperClassMethod"Veja que o R trata a variável sexo como sendo um “vetor de caracteres”. Mas nós sabemos que sexo é o nosso fator, então precisamos dar esta informação ao R. A função factor, transforma o vetor de caracteres em fator.
factor(sexo)## [1] Ma Ma Ma Ma Ma Fe Fe Fe Fe Fe
## Levels: Fe MaVeja que o R mostra os “valores” e depois mostra os níveis do fator. Agora podemos fazer o nosso gráfico adequadamente:
plot(factor(sexo),peso)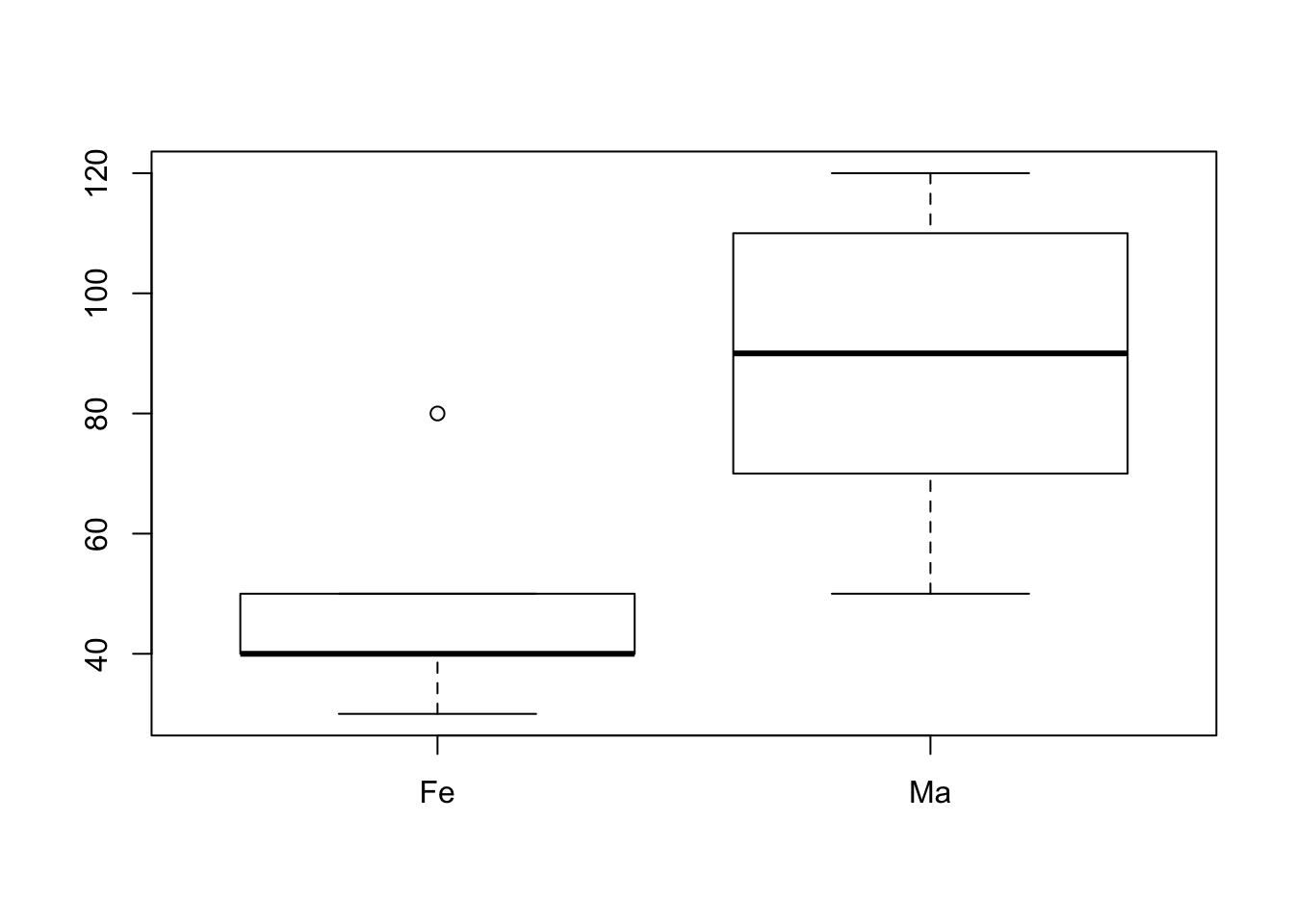
Gráficos do tipo boxplot são bons quando o número de observações (de dados) é muito grande. Neste caso, um gráfico com pontos seria melhor, pois podemos ver quantas observações foram utilizadas para produzir o gráfico. Para fazer um gráfico de pontos quando uma variável é categórica precisamos usar a função stripchart.
stripchart(peso~sexo) # faz o gráfico, mas na horizontal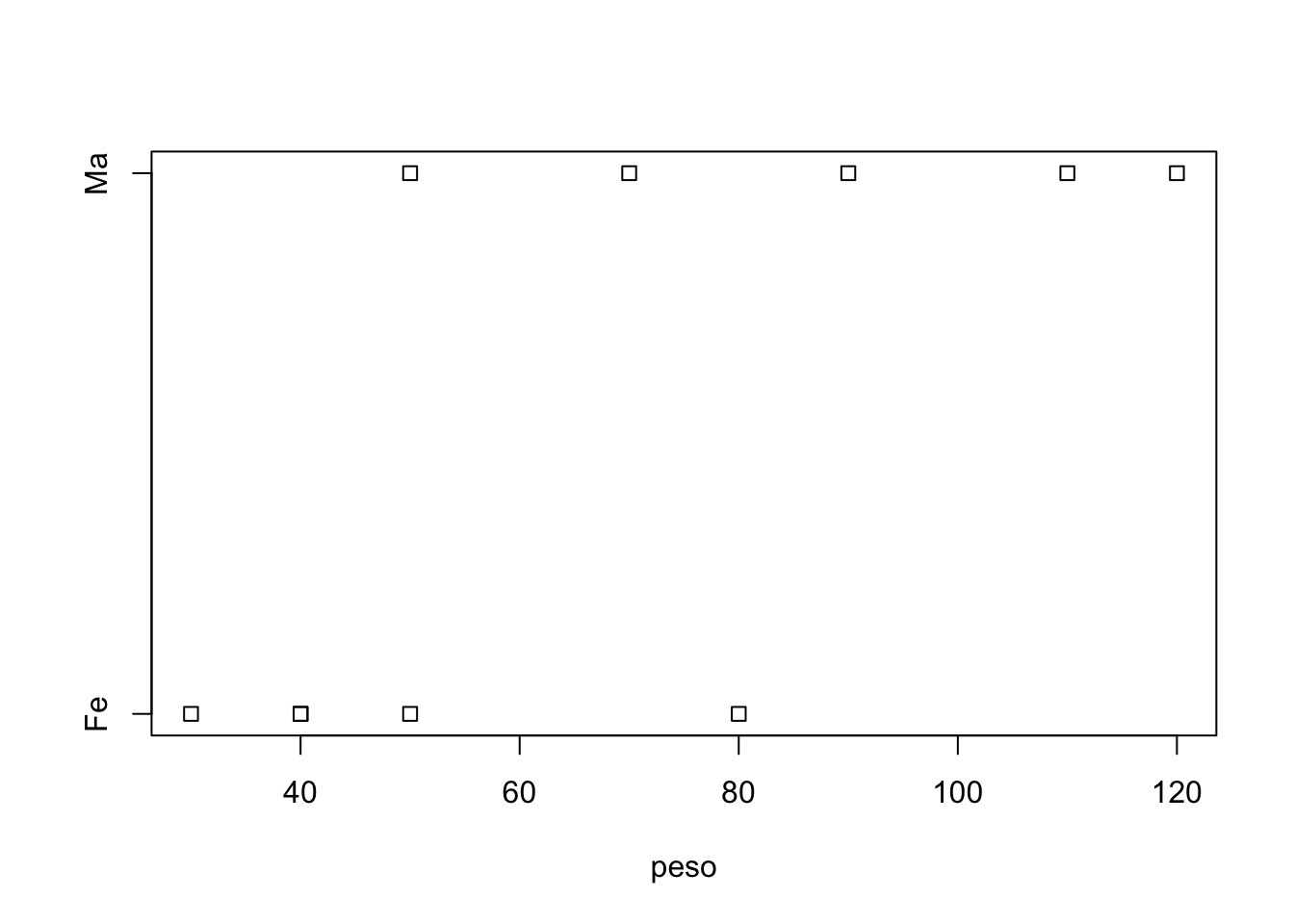
stripchart(peso~sexo,vertical=TRUE) Agora o gráfico está na vertical,porém os pontos aparecem nas extremidades. TRUE pode ser abreviado para apenas T.
Agora o gráfico está na vertical,porém os pontos aparecem nas extremidades. TRUE pode ser abreviado para apenas T.
stripchart(peso~sexo,vertical=T,at=c(1.3,1.7))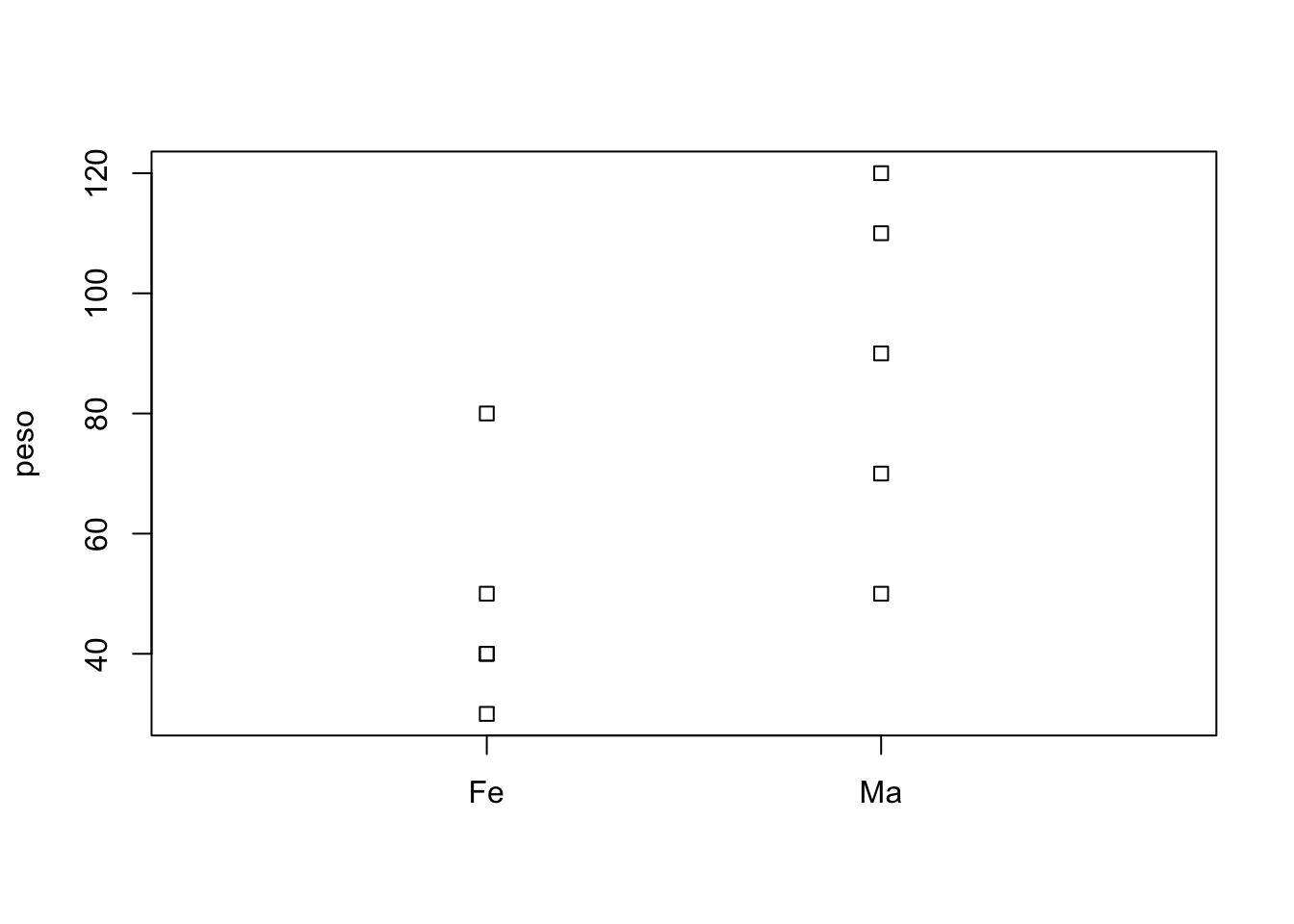 Note que agora só há um problema. Eram cinco fêmeas e no gráfico aparecem apenas 4. Isso ocorreu porque duas fêmeas tinham o mesmo peso. Para melhorar o gráfico é necessário usar o argumento method=“stack”, para que os pontos não fiquem sobrepostos.
Note que agora só há um problema. Eram cinco fêmeas e no gráfico aparecem apenas 4. Isso ocorreu porque duas fêmeas tinham o mesmo peso. Para melhorar o gráfico é necessário usar o argumento method=“stack”, para que os pontos não fiquem sobrepostos.
stripchart(peso~sexo,vertical=T,at=c(1.5,1.7),method="stack") 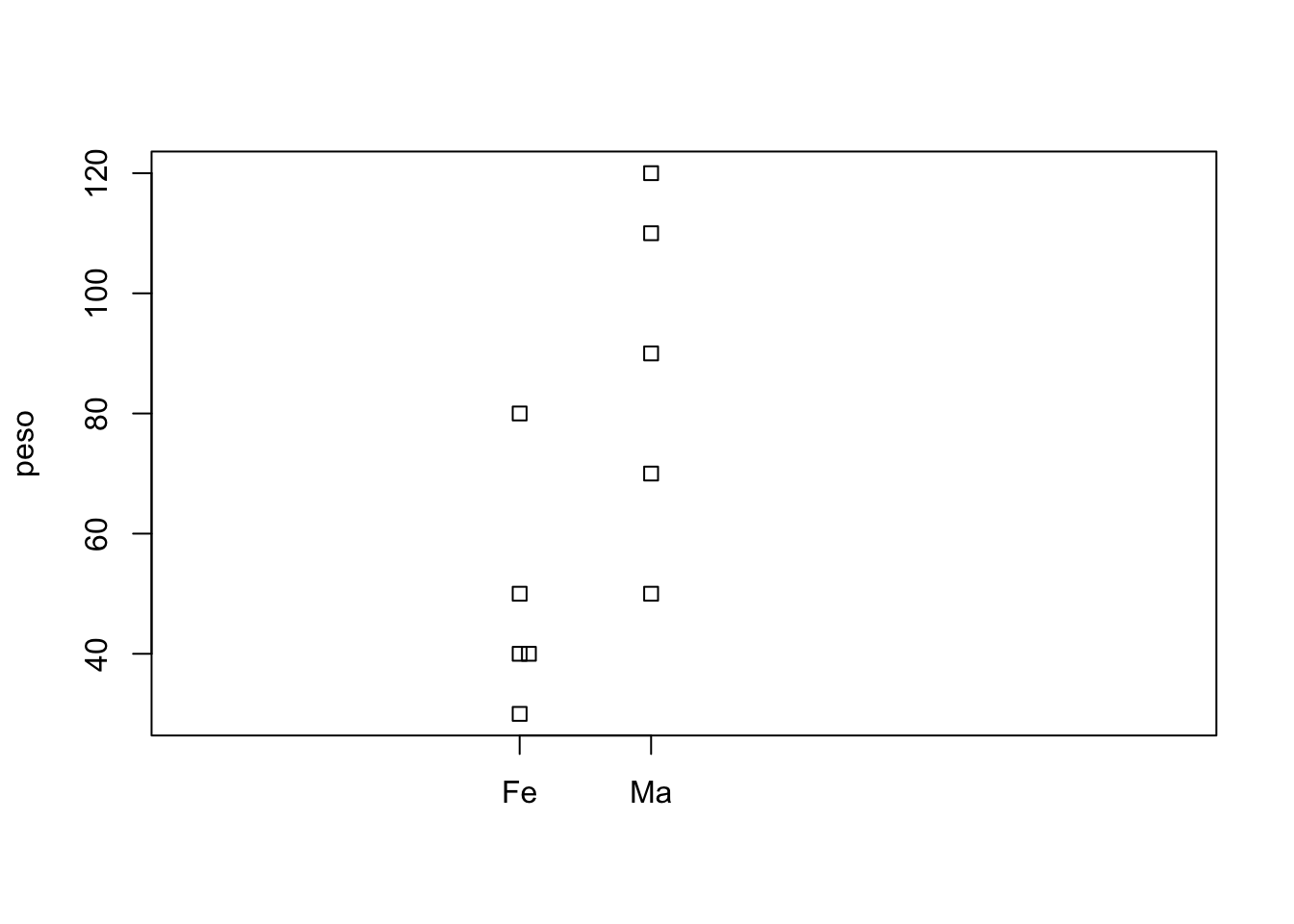 Os pontos não estão mais totalmente sobrepostos, mas um símbolo ainda está sobre o outro. Usando o argumento offset conseguimos separá-los
Os pontos não estão mais totalmente sobrepostos, mas um símbolo ainda está sobre o outro. Usando o argumento offset conseguimos separá-los
stripchart(peso~sexo,vertical=T,at=c(1.3,1.7),method= "stack",offset=1) 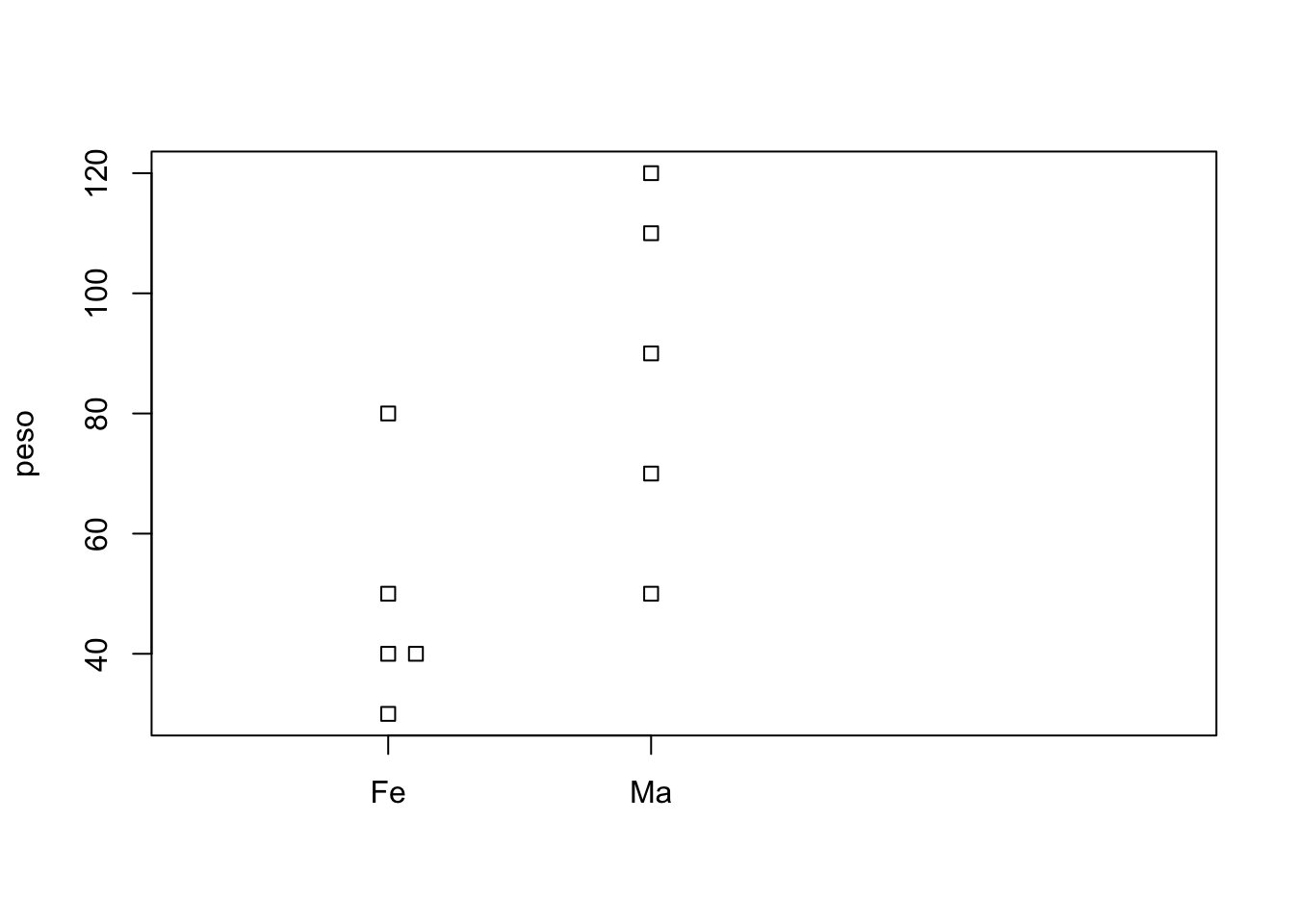
Exercícios com gráficos
Um biólogo interessado em saber se o número de aves está relacionado ao número de uma determinada espécie de árvore realizou amostras em 10 locais. Os valores obtidos foram: aves<-c(22,28,37,34,13,24,39,5,33,32) arvores<-c(25,26,40,30,10,20,35,8,35,28) Faça um gráfico que mostra a relação entre o número de aves e o número de
Um colega coletou mais dados sobre aves e árvores, em outra área, que podemos aproveitar. Os dados são: arvores2<-c(6,17,18,11,6,15,20,16,12,15) aves2<-c(7,15,12,14,4,14,16,60,13,16) Inclua estes novos pontos no gráfico com um símbolo diferente e cor azul.
Transformar vetores em matrizes e data frames
Além de importar tabelas, existe opções juntar vetores em um arquivo dataframe ou matriz. Para criar uma matriz use cbind (colum bind) ou rbind (row bind). Vamos ver como funciona. Vamos criar três vetores e depois juntá-los em uma matriz.
aa<-c(1,3,5,7,9)
bb<-c(5,6,3,8,9)
cc<-c("a","a","b","a","b")
cbind(aa,bb) # junta os vetores em colunas## aa bb
## [1,] 1 5
## [2,] 3 6
## [3,] 5 3
## [4,] 7 8
## [5,] 9 9rbind(aa,bb)## [,1] [,2] [,3] [,4] [,5]
## aa 1 3 5 7 9
## bb 5 6 3 8 9cbind(aa,bb,cc) ## aa bb cc
## [1,] "1" "5" "a"
## [2,] "3" "6" "a"
## [3,] "5" "3" "b"
## [4,] "7" "8" "a"
## [5,] "9" "9" "b"data.frame(aa,bb,cc)## aa bb cc
## 1 1 5 a
## 2 3 6 a
## 3 5 3 b
## 4 7 8 a
## 5 9 9 bteste = data.frame(aa,bb,cc)
teste[1,]## aa bb cc
## 1 1 5 ateste[,1]## [1] 1 3 5 7 9teste[3,3]## [1] b
## Levels: a bOperações com dataframe
teste[order(teste$bb),]## aa bb cc
## 3 5 3 b
## 1 1 5 a
## 2 3 6 a
## 4 7 8 a
## 5 9 9 bmean(teste$bb)## [1] 6.2mean(teste[2:5,2])## [1] 6.5tapply(teste$aa,teste$cc, mean)## a b
## 3.666667 7.000000