3
Manipulações
Manipulação de dados
Introdução
Esta seção trata do tema transformação de dados. Trata-se de uma tarefa dolorosa e demorada, tomando muitas vezes a maior parte do tempo de uma análise estatística. Essa etapa é essencial em qualquer análise de dados e, apesar de negligenciada pela academia, é decisiva para o sucesso de estudos aplicados.
Usualmente, o cientista de dados parte de uma base “crua” e a transforma até obter uma base de dados analítica. A base crua pode ser não estruturada, semi-estruturada ou estruturada. Já a base analítica é necessariamente estruturada e, a menos de transformações simples, está preparada para passar por análises estatísticas.
A figura abaixo mostra a fase de “disputa” com os dados (data wrangling) para deixá-los no formato analítico.
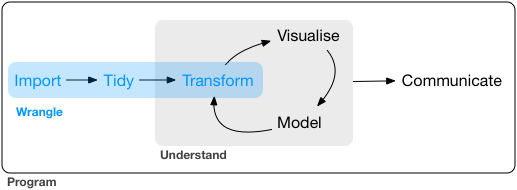
Data wrangling
Um conceito importante para obtenção de uma base analítica é o data tidying, ou arrumação de dados. Uma base é considerada tidy se
Cada linha da base representa uma observação. Cada coluna da base representa uma variável. Cada tabela considera informações de uma unidade amostral. A base de dados analítica é estruturada de tal forma que pode ser colocada diretamente em ambientes de modelagem estatística ou de visualização. Nem sempre uma base de dados analítica está no formato tidy, mas usualmente são necessários poucos passos para migrar de uma para outra. A filosofia tidy é a base do tidyverse.
Os principais pacotes encarregados da tarefa de estruturar os dados são o dplyr e o tidyr. Eles serão o tema desse tópico. Instale e carregue os pacotes utilizando:
#install.packages("dplyr")
#install.packages("tidyr")
library(dplyr)##
## Attaching package: 'dplyr'## The following objects are masked from 'package:stats':
##
## filter, lag## The following objects are masked from 'package:base':
##
## intersect, setdiff, setequal, unionlibrary(tidyr)Trabalhando com tibbles%>%
Uma tibble nada mais é do que um data.frame, mas com um método de impressão mais adequado.
As tibbles são parte do pacote tibble. Assim, para começar a usá-las, instale e carregue o pacote.
#install.packages("tibble")
library(tibble)Mais informações sobre tibbles podem ser encontradas neste link.
Nessa seção, vamos trabalhar com uma base simplificada do PNUD (Programa das Nações Unidas para o Desenvolvimento), contendo informações socioeconômicas de todos os municípios do país. Os resultados foram obtidos a partir dos Censos de 1991, 2000 e 2010.
A base contém 16686 linhas e 14 colunas, descritas abaixo:
ano - Ano do Censo utilizado como base para cálculo do IDH-Municipal e outras métricas. muni - Nome do município. Cada município aparece três vezes, um para cada ano. uf - Unidade Federativa. regiao - Região brasileira. idhm - IDH municipal, dividido em idhm_e - IDH municipal - educação. idhm_l - IDH municipal - longevidade. idhm_r - IDH municipal - renda. espvida - Expectativa de vida. rdpc - Renda per capita. gini - Coeficiente de gini municipal (mede desigualdade social). pop - População residente do município. lat, lon - Latitude e longitude do município (ponto médio). Para acessar esta base, instale e carregue o pacote abjData da seguinte maneira:
#devtools::install_github("abjur/abjData")
library(abjData)Assim, utilizaremos o objeto pnud_min para acessar os dados.
pnud_min## # A tibble: 16,686 x 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini pop
## <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <int>
## 1 1991 ALTA… RO Norte 0.329 0.112 0.617 0.516 62.0 198. 0.63 22835
## 2 1991 ARIQ… RO Norte 0.432 0.199 0.684 0.593 66.0 319. 0.570 55018
## 3 1991 CABI… RO Norte 0.309 0.108 0.636 0.43 63.2 116. 0.7 5846
## 4 1991 CACO… RO Norte 0.407 0.171 0.667 0.593 65.0 320. 0.66 66534
## 5 1991 CERE… RO Norte 0.386 0.167 0.629 0.547 62.7 240. 0.6 19030
## 6 1991 COLO… RO Norte 0.376 0.151 0.658 0.536 64.5 225. 0.62 25070
## 7 1991 CORU… RO Norte 0.203 0.039 0.572 0.373 59.3 81.4 0.59 10737
## 8 1991 COST… RO Norte 0.425 0.22 0.629 0.553 62.8 250. 0.65 6902
## 9 1991 ESPI… RO Norte 0.388 0.159 0.653 0.561 64.2 263. 0.63 22505
## 10 1991 GUAJ… RO Norte 0.468 0.247 0.662 0.625 64.7 391. 0.6 31240
## # … with 16,676 more rows, and 2 more variables: lat <dbl>, lon <dbl>Veja que, por padrão, apenas as dez primeiras linhas da tibble são impressas na tela. Além disso, as colunas que não couberem na largura do console serão omitidas. Também são apresentadas a dimensão da tabela e as classes de cada coluna.
O pacote dplyr
O dplyr é o pacote mais útil para realizar transformação de dados, aliando simplicidade e eficiência de uma forma elegante. Os scripts em R que fazem uso inteligente dos verbos dplyr e as facilidades do operador pipe tendem a ficar mais legíveis e organizados sem perder velocidade de execução.
As principais funções do dplyr são:
filter() - filtra linhas select() - seleciona colunas mutate() - cria/modifica colunas arrange() - ordena a base summarise() - sumariza a base Todas essas funções seguem as mesmas características:
O input é sempre uma tibble e o output é sempre um tibble. Colocamos o tibble no primeiro argumento e o que queremos fazer nos outros argumentos. A utilização é facilitada com o emprego do operador %>%. O pacote faz uso extensivo de NSE (non standard evaluation). As principais vantagens de se usar o dplyr em detrimento das funções do R base são:
Manipular dados se torna uma tarefa muito mais simples. O código fica mais intuitivo de ser escrito e mais simples de ser lido. O pacote dplyr utiliza C e C++ por trás da maioria das funções, o que geralmente torna o código mais eficiente. É possível trabalhar com diferentes fontes de dados, como bases relacionais (SQL) e data.table. Agora, vamos avaliar com mais detalhes os principais verbos do pacote dplyr.
select()
A função select() seleciona colunas (variáveis). É possível utilizar nomes, índices, intervalos de variáveis ou utilizar as funções starts_with(x), contains(x), matches(x), one_of(x) para selecionar as variáveis.
pnud_min %>%
select(ano, regiao, muni)## # A tibble: 16,686 x 3
## ano regiao muni
## <int> <chr> <chr>
## 1 1991 Norte ALTA FLORESTA D'OESTE
## 2 1991 Norte ARIQUEMES
## 3 1991 Norte CABIXI
## 4 1991 Norte CACOAL
## 5 1991 Norte CEREJEIRAS
## 6 1991 Norte COLORADO DO OESTE
## 7 1991 Norte CORUMBIARA
## 8 1991 Norte COSTA MARQUES
## 9 1991 Norte ESPIGÃO D'OESTE
## 10 1991 Norte GUAJARÁ-MIRIM
## # … with 16,676 more rowspnud_min %>%
select(ano:regiao, rdpc)## # A tibble: 16,686 x 5
## ano muni uf regiao rdpc
## <int> <chr> <chr> <chr> <dbl>
## 1 1991 ALTA FLORESTA D'OESTE RO Norte 198.
## 2 1991 ARIQUEMES RO Norte 319.
## 3 1991 CABIXI RO Norte 116.
## 4 1991 CACOAL RO Norte 320.
## 5 1991 CEREJEIRAS RO Norte 240.
## 6 1991 COLORADO DO OESTE RO Norte 225.
## 7 1991 CORUMBIARA RO Norte 81.4
## 8 1991 COSTA MARQUES RO Norte 250.
## 9 1991 ESPIGÃO D'OESTE RO Norte 263.
## 10 1991 GUAJARÁ-MIRIM RO Norte 391.
## # … with 16,676 more rowspnud_min %>%
select(ano, starts_with('idhm'))## # A tibble: 16,686 x 5
## ano idhm idhm_e idhm_l idhm_r
## <int> <dbl> <dbl> <dbl> <dbl>
## 1 1991 0.329 0.112 0.617 0.516
## 2 1991 0.432 0.199 0.684 0.593
## 3 1991 0.309 0.108 0.636 0.43
## 4 1991 0.407 0.171 0.667 0.593
## 5 1991 0.386 0.167 0.629 0.547
## 6 1991 0.376 0.151 0.658 0.536
## 7 1991 0.203 0.039 0.572 0.373
## 8 1991 0.425 0.22 0.629 0.553
## 9 1991 0.388 0.159 0.653 0.561
## 10 1991 0.468 0.247 0.662 0.625
## # … with 16,676 more rowsfilter()
A função filter() filtra linhas. Ela é semelhante à função subset(), do R base.
pnud_min %>%
select(ano, muni, uf) %>%
filter(uf == 'RS')## # A tibble: 1,485 x 3
## ano muni uf
## <int> <chr> <chr>
## 1 1991 ACEGUÁ RS
## 2 1991 ÁGUA SANTA RS
## 3 1991 AGUDO RS
## 4 1991 AJURICABA RS
## 5 1991 ALECRIM RS
## 6 1991 ALEGRETE RS
## 7 1991 ALEGRIA RS
## 8 1991 ALMIRANTE TAMANDARÉ DO SUL RS
## 9 1991 ALPESTRE RS
## 10 1991 ALTO ALEGRE RS
## # … with 1,475 more rowsPara fazer várias condições, use os operadores lógicos & e | ou separe filtros entre vírgulas.
pnud_min %>%
select(ano, regiao, uf, idhm) %>%
filter(uf %in% c('SP', 'MG') | idhm > .5, ano == 2010)## # A tibble: 5,527 x 4
## ano regiao uf idhm
## <int> <chr> <chr> <dbl>
## 1 2010 Norte RO 0.641
## 2 2010 Norte RO 0.702
## 3 2010 Norte RO 0.65
## 4 2010 Norte RO 0.718
## 5 2010 Norte RO 0.692
## 6 2010 Norte RO 0.685
## 7 2010 Norte RO 0.613
## 8 2010 Norte RO 0.611
## 9 2010 Norte RO 0.672
## 10 2010 Norte RO 0.657
## # … with 5,517 more rowsRepare que o operador %in% é muito útil para trabalhar com vetores. O resultado da operação é um vetor lógico o tamanho do vetor do elemento da esquerda, identificando quais elementos da esquerda batem com algum elemento da direita.
Também podemos usar funções que retornam valores lógicos, como a str_detect().
library(stringr)
pnud_min %>%
select(muni, ano, uf) %>%
filter(str_detect(muni, '^[HG]|S$'),
ano == 1991)## # A tibble: 970 x 3
## muni ano uf
## <chr> <int> <chr>
## 1 ARIQUEMES 1991 RO
## 2 CEREJEIRAS 1991 RO
## 3 COSTA MARQUES 1991 RO
## 4 GUAJARÁ-MIRIM 1991 RO
## 5 ALTO ALEGRE DOS PARECIS 1991 RO
## 6 BURITIS 1991 RO
## 7 CASTANHEIRAS 1991 RO
## 8 GOVERNADOR JORGE TEIXEIRA 1991 RO
## 9 PARECIS 1991 RO
## 10 SERINGUEIRAS 1991 RO
## # … with 960 more rowsmutate()
A função mutate() cria ou modifica colunas. Ela é equivalente à função transform(), mas aceita várias novas colunas iterativamente. Novas variáveis devem ter o mesmo número de linhas da base original (ou terem comprimento 1).
pnud_min %>%
select(muni, rdpc, pop, idhm_l, espvida) %>%
mutate(renda = rdpc * pop,
razao = idhm_l / espvida)## # A tibble: 16,686 x 7
## muni rdpc pop idhm_l espvida renda razao
## <chr> <dbl> <int> <dbl> <dbl> <dbl> <dbl>
## 1 ALTA FLORESTA D'OESTE 198. 22835 0.617 62.0 4531834. 0.00995
## 2 ARIQUEMES 319. 55018 0.684 66.0 17576600. 0.0104
## 3 CABIXI 116. 5846 0.636 63.2 680357. 0.0101
## 4 CACOAL 320. 66534 0.667 65.0 21306848. 0.0103
## 5 CEREJEIRAS 240. 19030 0.629 62.7 4569103 0.0100
## 6 COLORADO DO OESTE 225. 25070 0.658 64.5 5636237. 0.0102
## 7 CORUMBIARA 81.4 10737 0.572 59.3 873777. 0.00964
## 8 COSTA MARQUES 250. 6902 0.629 62.8 1726052. 0.0100
## 9 ESPIGÃO D'OESTE 263. 22505 0.653 64.2 5919490. 0.0102
## 10 GUAJARÁ-MIRIM 391. 31240 0.662 64.7 12226399. 0.0102
## # … with 16,676 more rowsarrange()
A função arrange() ordena a base. O argumento desc= pode ser utilizado para gerar uma ordem decrescente.
pnud_min %>%
filter(ano == 2010) %>%
arrange(desc(espvida))## # A tibble: 5,562 x 14
## ano muni uf regiao idhm idhm_e idhm_l idhm_r espvida rdpc gini
## <int> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 2010 BLUM… SC Sul 0.806 0.722 0.894 0.812 78.6 1253. 0.46
## 2 2010 BRUS… SC Sul 0.795 0.707 0.894 0.794 78.6 1117. 0.4
## 3 2010 BALN… SC Sul 0.845 0.789 0.894 0.854 78.6 1626. 0.52
## 4 2010 RIO … SC Sul 0.802 0.727 0.894 0.793 78.6 1114. 0.45
## 5 2010 RANC… SC Sul 0.753 0.644 0.893 0.743 78.6 814. 0.42
## 6 2010 RIO … SC Sul 0.754 0.625 0.892 0.769 78.5 957. 0.47
## 7 2010 IOME… SC Sul 0.795 0.749 0.891 0.754 78.4 874. 0.33
## 8 2010 JOAÇ… SC Sul 0.827 0.771 0.891 0.823 78.4 1338. 0.54
## 9 2010 NOVA… SC Sul 0.748 0.628 0.891 0.749 78.4 848. 0.35
## 10 2010 PORT… SC Sul 0.786 0.724 0.891 0.752 78.4 864. 0.53
## # … with 5,552 more rows, and 3 more variables: pop <int>, lat <dbl>, lon <dbl>summarise%>%
A função summarise() sumariza a base. Ela aplica uma função às variáveis, retornando um vetor de tamanho 1. Geralmente ela é utilizada em conjunto da função group_by().
pnud_min %>%
group_by(regiao, uf) %>%
summarise(n = n(), espvida = mean(espvida)) %>%
arrange(regiao, desc(espvida))## # A tibble: 27 x 4
## # Groups: regiao [5]
## regiao uf n espvida
## <chr> <chr> <int> <dbl>
## 1 Centro-Oeste DF 3 73.4
## 2 Centro-Oeste GO 735 70.0
## 3 Centro-Oeste MS 234 69.9
## 4 Centro-Oeste MT 423 69.4
## 5 Nordeste CE 552 65.6
## 6 Nordeste RN 501 65.1
## 7 Nordeste PE 555 64.9
## 8 Nordeste BA 1251 64.6
## 9 Nordeste SE 225 64.3
## 10 Nordeste PI 672 64.0
## # … with 17 more rowscount()
A função count() também pode ser usada para sumarizar em relação à frequência.
pnud_min %>%
filter(ano == 2010) %>%
count(regiao, sort = TRUE) %>%
mutate(prop = n / sum(n), prop = scales::percent(prop))## # A tibble: 5 x 3
## regiao n prop
## <chr> <int> <chr>
## 1 Nordeste 1794 32.3%
## 2 Sudeste 1667 30.0%
## 3 Sul 1187 21.3%
## 4 Centro-Oeste 465 8.4%
## 5 Norte 449 8.1%